Model fusing (combining fine-tuned adapters to the base model) with [mlx-lm] - unintended behavior
April 25, 2026NLP
Motivation
In the last post, I introduced a recently fine-tuned multi-entity Sentiment analysis model, which I have been using daily as part of the financial news pipeline.
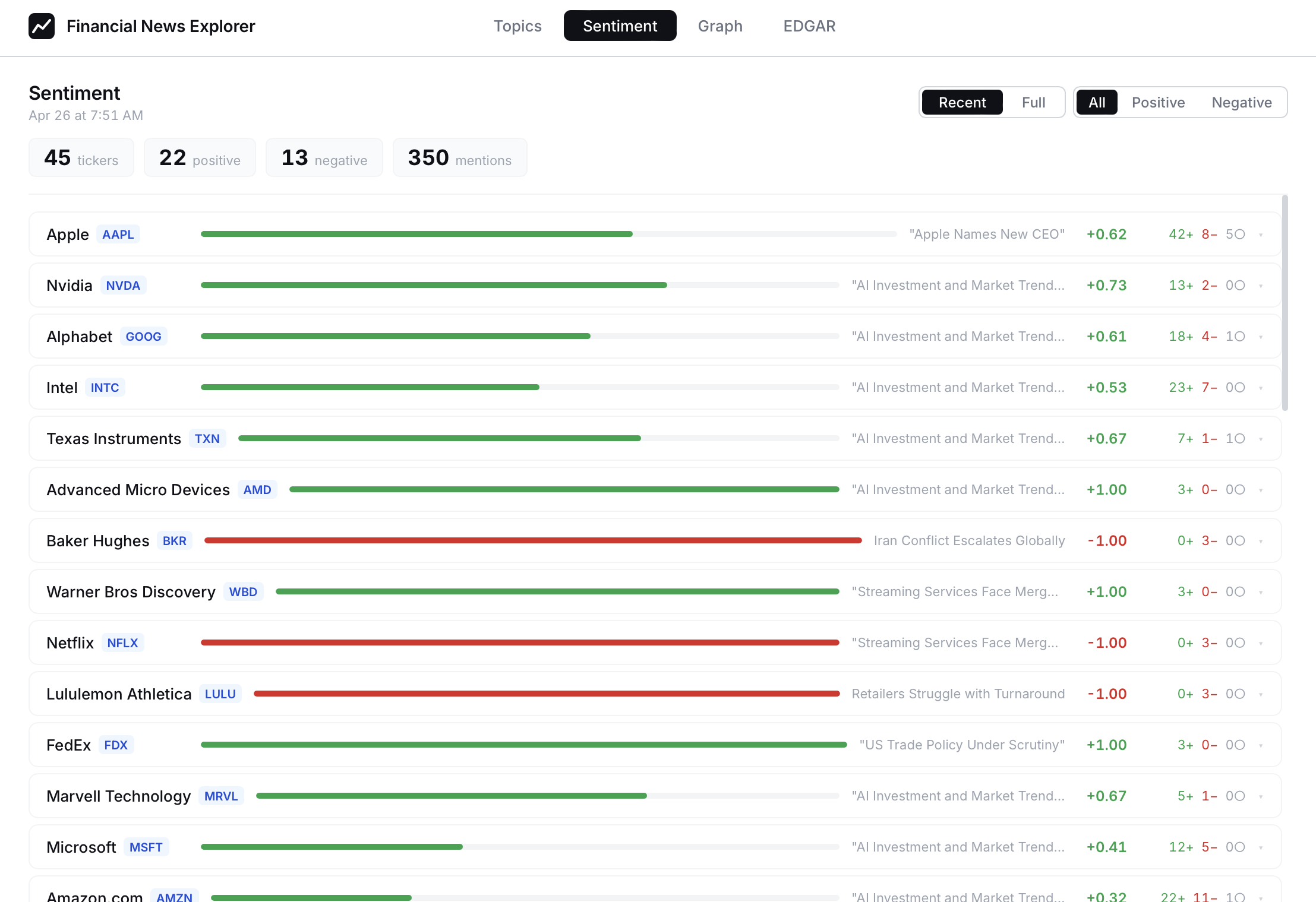
While the eval results on 20 sample dataset looked fine, as I applied the model to the actual pipeline, the problem started to appear (which is expected due to the small base model size, i.e., Llama 3.2 3B).
| Metric | Llama 3.2 3B (Fine-tuned) |
|---|---|
| Perfect records | 65% |
| Entity Precision | 97.4% |
| Entity Recall | 92.7% |
| Entity F1 | 95.0% |
| Polarity Accuracy | 89.5% |
As this shows, somehow, the analyzed sentiments are too positive.
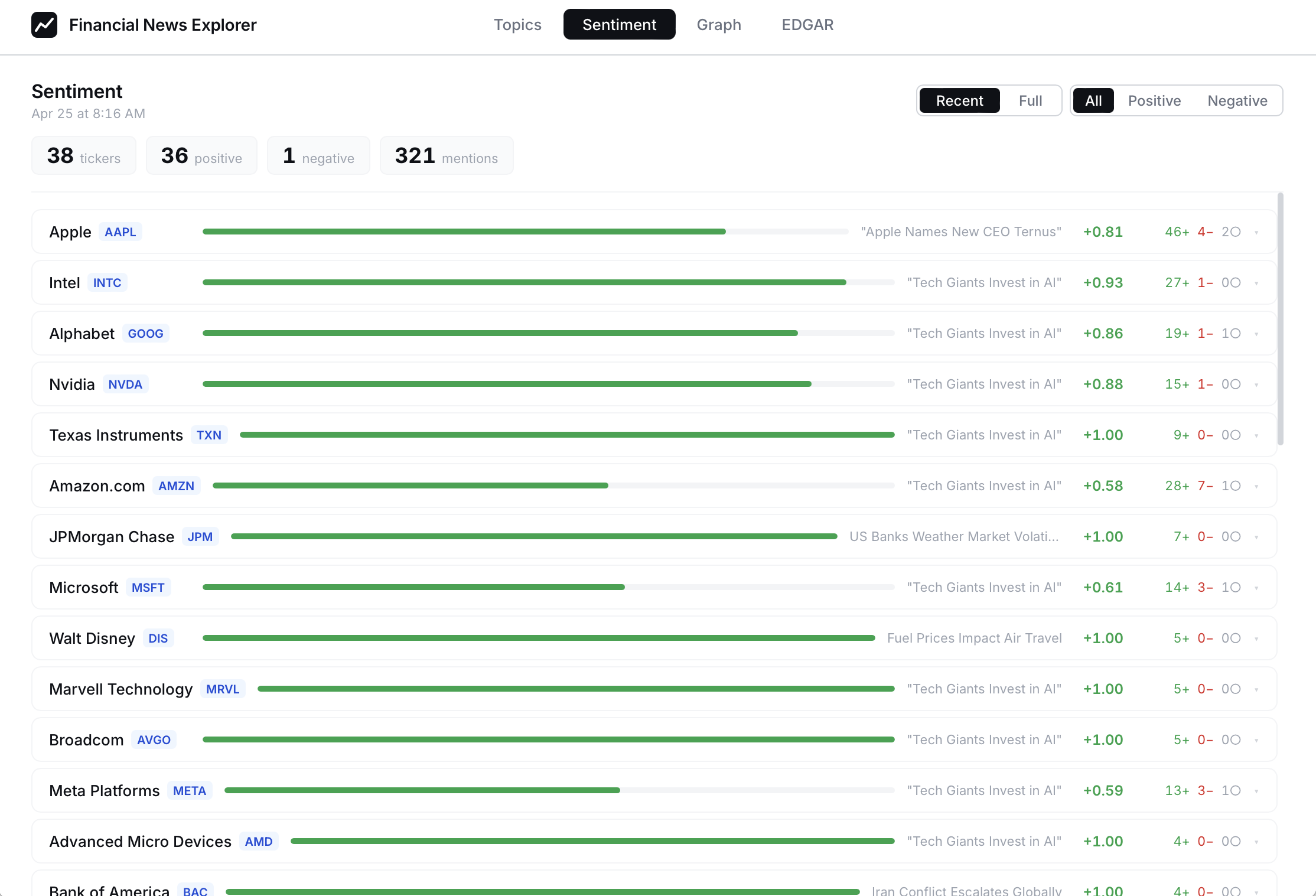
I knew it's time to revisit the re-training stage.
Evaluation
In contrast to my expectations, the evaluation results based on 30 samples (10 added), showed weird results that the evaluation with the newly trainined model showed inferior results.
| Metric | Deployed | Newly Trained |
|---|---|---|
| Perfect records | 36.7% | 33.3% |
| Entity Precision | 77.4% | 80.3% |
| Entity Recall | 90.6% | 92.5% |
| Entity F1 | 83.5% | 86.0% |
| Polarity Accuracy | 66.7% | 53.1% |
Especially, Polarity Accuracy metic here is significantly worsened (66.7% -> 53.1%).
Interestingly (and problematically), this doesn't match the metrics of using the local adapter (non-fused model), respectively.
| Metric | Original (Deployed) | Original (Adapter) | Newly Trained (Deployed) | Newly Trained (Adapter) |
|---|---|---|---|---|
| Perfect records | 36.7% | 53.3% | 33.3% | 53.3% |
| Entity Precision | 77.4% | 87.9% | 80.3% | 86.4% |
| Entity Recall | 90.6% | 96.2% | 92.5% | 96.2% |
| Entity F1 | 83.5% | 91.9% | 86.0% | 91.1% |
| Polarity Accuracy | 66.7% | 78.4% | 53.1% | 80.4% |
Possible bug?
As reported in the mlx-lm GitHub, it turned out that I wasn't only one who encountered this issue. Unfortunately, since the root cause is unknown (unlike in this issue report, Llama 3.2 3B doesn't use MoE architecture), other than using adapters, no clear mitiigation seems to exist for now.
Not so biased
By separating the base model and the fine-tuned adapter, the sentiment is now balanced.